-

- 北京天演融智软件有限公司
-
全国服务咨询热线:
18510103847
18510103847




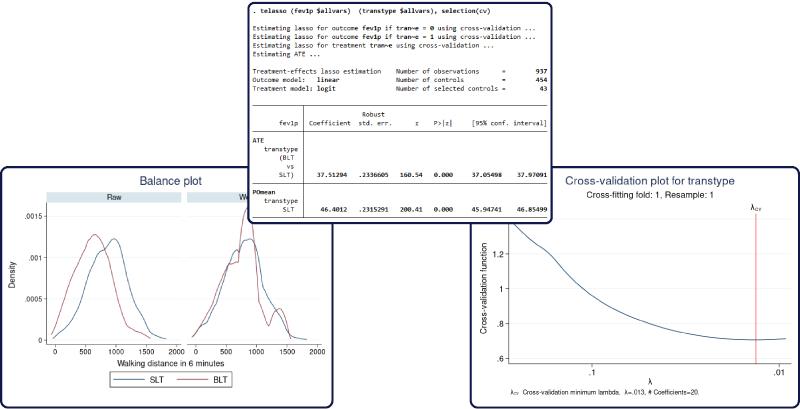
产品描述


您是第3296477位访客
版权所有 ©2025 八方资源网 粤ICP备10089450号-8
北京天演融智软件有限公司 保留所有权利.
北京天演融智软件有限公司 保留所有权利.
技术支持: 八方资源网 八方供应信息 投诉举报 网站地图手机网站

微信号码
地址:北京市 海淀区 北京市海淀区上地东路35号院1号楼3层1-312-318、1-312-319
联系人:王经理女士
微信帐号:18510103847

















