使用期限租赁或*
许可形式单机和网络版
原产地美国
介质下载
适用平台window,mac,linux
科学软件网提供软件和培训服务已有19年,拥有丰富的经验,提供软件产品上千款,涵盖领域包括经管,仿真,地球地理,生物化学,工程科学,排版及网络管理等。同时还有的服务,现场培训+课程,以及本地化服务。
anyvalue(), anymatch(), and anycount() are for categorical or other variables taking integer
values. If we define a subset of values specified by an integer numlist (see [U] 11.1.8 numlist),
anyvalue() extracts the subset, leaving every other value missing; anymatch() defines an indicator
variable (1 if in subset, 0 otherwise); and anycount() counts occurrences of the subset across a set
of variables. Therefore, with one variable, anymatch(varname) and anycount(varname) are
equivalent.
With the auto dataset, we can generate a variable containing the high values of rep78 and a
variable indicating whether rep78 has a high value:
In Bayesian analysis, we can use previous information, either belief or experimental evidence, in
a data model to acquire more balanced results for a particular problem. For example, incorporating
prior information can mitigate the effect of a small sample size. Importantly, the use of the prior
evidence is achieved in a theoretically sound and principled way.
By using the knowledge of the entire posterior distribution of model parameters, Bayesian inference
is far more comprehensive and flexible than the traditional inference.
Bayesian inference is exact, in the sense that estimation and prediction are based on the posterior
distribution. The latter is either known analytically or can be estimated numerically with an arbitrary
precision. In contrast, many frequentist estimation procedures such as maximum likelihood rely on
the assumption of asymptotic normality for inference.

值得信任
技术支持
我们不仅编写统计方法,我们还会进行验证。
您能从Stata estimator rest与其他估计的比较中看到Monte-Carlo模拟的一致性和覆盖率以及我们统计学家们进行的广
泛测试。每一版的Stata软件,我们都通过了各种认证,包括230万行的代码测试,并产生了430万行的结果输出。我们验
证了这430万行代码中的每一个数字和每一段文字。

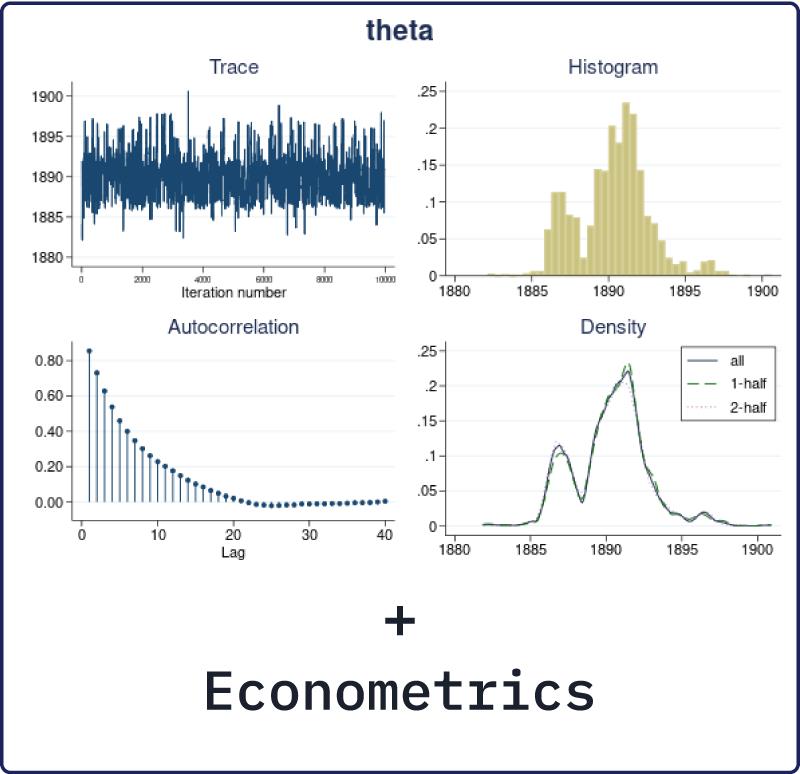
How to do Bayesian analysis
Bayesian analysis starts with the specification of a posterior model. The posterior model describes
the probability distribution of all model parameters conditional on the observed data and some prior
knowledge. The posterior distribution has two components: a likelihood, which includes information
about model parameters based on the observed data, and a prior, which includes prior information
(before observing the data) about model parameters. The likelihood and prior models are combined
using the Bayes rule to produce the posterior distribution
科学软件网为全国大多数高校提供过产品或服务,销售和售后团队,确保您售后**!
http://turntech8843.b2b168.com


























