使用期限租赁或*
许可形式单机和网络版
原产地美国
介质下载
适用平台window,mac,linux
科学软件网提供的软件上千款,涉及所有学科领域,您所需的软件,我们都能提供。科学软件网提供的软件涵盖领域包括经管,仿真,地球地理,生物化学,工程科学,排版及网络管理等。同时,还提供培训、课程(包含34款软件,66门课程)、实验室解决方案和项目咨询等服务。
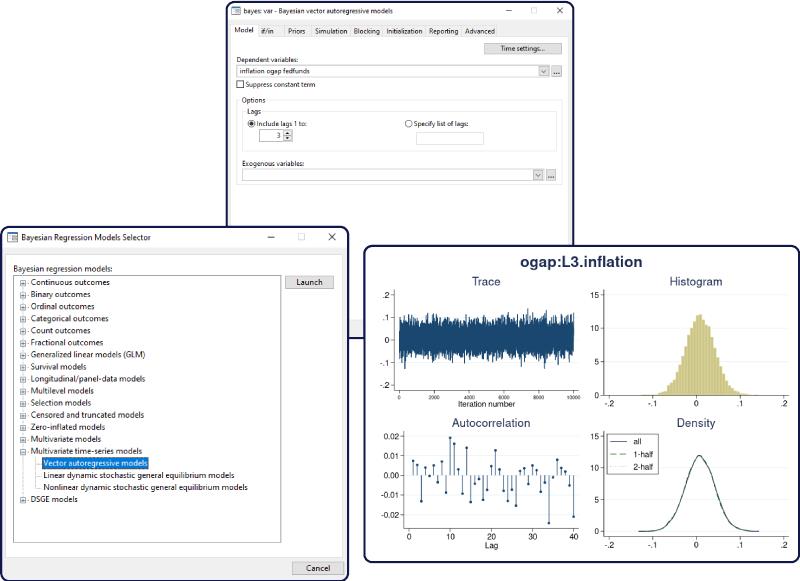
In Bayesian analysis, we seek a balance between prior information in a form of expert knowledge
or belief and evidence from data at hand. Achieving the right balance is one of the difficulties in
Bayesian modeling and inference. In general, we should not allow the prior information to overwhelm
the evidence from the data, especially when we have a large data sample. A famous theoretical
result, the Bernstein–von Mises theorem, states that in large data samples, the posterior distribution is
independent of the prior distribution and, therefore, Bayesian and likelihood-based inferences should
yield essentially the same results. On the other hand, we need a strong enough prior to support weak
evidence that usually comes from insufficient data. It is always good practice to perform sensitivity
analysis to check the dependence of the results on the choice of a prior.

Stata 16 Feature highlights:
1. Lasso
2. Reporting
3. Meta-analysis
4. Choice models
5. Python integration
6. New in Bayesian analysis—Multiple chains, predictions, and more
7. Panel-data ERMs
8. Import data from SAS and SPSS
9. Nonparametric series regression
10. Multiple datasets in memory
11. Sample-size analysis for confidence intervals
12. Nonlinear DSGE models
13. Multiple-group IRT models
14. xtheckman
15. Multiple-dose pharmacokinetic modeling
16. Heteroskedastic ordered probit models
17. Graph sizes in printer points, centimeters, and inches
18. Numerical integration
19. Linear programming
20. Stata in Korean
21. Mac interface now supports Dark Mode and native tabbed windows
22. Do-file Editor—Autocompletion and more syntax highlighting

Frequentist inference is based on the sampling distributions of estimators of parameters and provides
parameter point estimates and their standard errors as well as confidence intervals. The exact sampling
distributions are rarely known and are often approximated by a large-sample normal distribution.
Bayesian inference is based on the posterior distribution of the parameters and provides summaries of
this distribution including posterior means and their MCMC standard errors (MCSE) as well as credible
intervals. Although exact posterior distributions are known only in a number of cases, general posterior
distributions can be estimated via, for example, Markov chain Monte Carlo (MCMC) sampling without
any large-sample approximation.
Frequentist confidence intervals do not have straightforward probabilistic interpretations as do
Bayesian credible intervals. For example, the interpretation of a 95% confidence interval is that if
we repeat the same experiment many times and compute confidence intervals for each experiment,
then 95% of those intervals will contain the true value of the parameter. For any given confidence
interval, the probability that the true value is in that interval is either zero or one, and we do not
know which. We may only infer that any given confidence interval provides a plausible range for the
true value of the parameter. A 95% Bayesian credible interval, on the other hand, provides a range
for a parameter such that the probability that the parameter lies in that range is 95%.
In Stata 16, you can embed and execute Python code from within Stata. Stata's new python command allows you to easily call Python from Stata and output Python results within Stata.
You can invoke Python interactively or in do-files and ado-files so that you can leverage Python's extensive language features. You can also execute a Python file (.py) directly through Stata.
In addition, we introduced the Stata Function Interface (sfi) Python module, which provides a bi-directional connection between Stata and Python. This module lets you access Stata's current dataset, frames, macros, scalars, matrices, value labels, characteristics, global Mata matrices, and more.
All of this means that you can now use any Python package directly within Stata. For instance, you can use Matplotlib to draw 3-dimensional graphs. You can use NumPy for numerical computations. You can use Scrapy to scrape data from the web. You can access additional machine-learning techniques such as neural networks and support vector machines through TensorFlow and scikit-learn. And much more.
Finally, Stata’s Do-file Editor now includes syntax highlighting for the Python language.
While advanced users and programmers might be most likely to take advantage of Python integration, the availability of Python within Stata will excite many more users in all disciplines.
科学软件网专注提供正版软件,跟上百家软件开发商有紧密合作,价格优惠,的和培训服务。
http://turntech8843.b2b168.com


























