使用期限租赁或*
许可形式单机和网络版
原产地美国
介质下载
适用平台window,mac,linux
科学软件网销售软件达19年,有丰富的销售经验以及客户资源,提供的产品涵盖各个学科,包括经管,仿真,地球地理,生物化学,工程科学,排版及网络管理等。此外,我们还提供很多附加服务,如:现场培训、课程、解决方案、咨询服务等。
anyvalue(), anymatch(), and anycount() are for categorical or other variables taking integer
values. If we define a subset of values specified by an integer numlist (see [U] 11.1.8 numlist),
anyvalue() extracts the subset, leaving every other value missing; anymatch() defines an indicator
variable (1 if in subset, 0 otherwise); and anycount() counts occurrences of the subset across a set
of variables. Therefore, with one variable, anymatch(varname) and anycount(varname) are
equivalent.
With the auto dataset, we can generate a variable containing the high values of rep78 and a
variable indicating whether rep78 has a high value:

Multiple-group IRT models in Stata
IRT models explore the relationship between a latent (unobserved) trait and items that measure aspects of the trait. This often arises in standardized testing where the trait of interest is ability, such as mathematical ability. A set of items (test questions) is designed, and the responses measure this unobserved trait. Researchers in education, psychology, and health frequently fit IRT models.
Stata’s irt commands fit 1-, 2-, and 3-parameter logistic models. They also fit graded response, nominal response, partial credit, and rating scale models, and any combination of them. And after fitting a model, irtgraph graphs item-characteristic curves, test characteristic curves, item information functions, and test information functions.
New in Stata 16, the irt commands allow comparisons across groups. Take any of the existing irt commands, add a group(varname) option, and fit the corresponding multiple-group model. For instance, type
. irt 2pl item1-item10, group(female)
and fit a two-group 2PL model.
Group-specific means and variances of the latent trait will be estimated. Group-specific difficulty and discrimination parameters can also be estimated for one or more items. With constraints, you can specify exactly which parameters are allowed to vary and which parameters are constrained to be equal across groups.
You can even use likelihood-ratio tests to compare models with and without constraints to perform an IRT model-based test of differential item functioning.
summarize displays the mean and standard deviation of a variable across observations; program
writers can access the mean in r(mean) and the standard deviation in r(sd) (see [R] summarize).
egen’s rowmean() function creates the means of observations across variables. rowmedian() creates
the medians of observations across variables. rowpctile() returns the #th percentile of the variables
specified in varlist. rowsd() creates the standard deviations of observations across variables.
rownonmiss() creates a count of the number of nonmissing observations, the denominator of the
rowmean() calculation

2019年6月Stata 15正式发布。这是Stata有史以来大的一次版本更新。我们贴出了Statalist并且列出了16项重要的新功能。这篇文章会重点谈谈这些新功能:
扩展回归模型
潜在类别分析(LCA)
贝叶斯前缀指令
线性动态随机一般均衡(DSGE)模型
web 的动态Markdown文档
非线性混合效应模型
空间自回归模型(SAR)
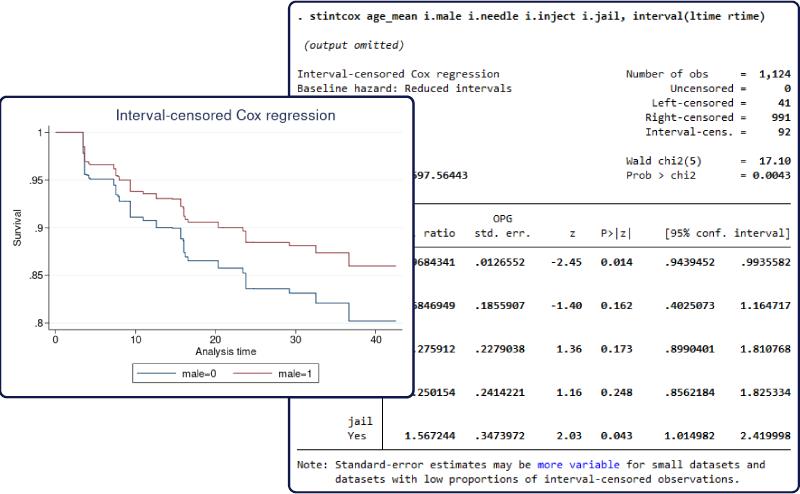
区间删失参数生存时间模型
有限混合模型(FMMs)
混合Logit模型
非参数回归
聚类随机设计和回归模型的功率分析
Word和PDF文档
图形颜色透明度/不透明度
ICD-10-CM/PCS支持
联邦储备经济数据(FRED)支持
其他
上面列出的十六功能当然是重要的, 但还有其他值得一提的。比较*想到的是:
. 贝叶斯多级模型
. 门限回归
. 具有随机系数的面板数据tobit
. 区间测量结果的多层回归
. 删失结果的多级Tobit回归
. 面板数据的协整测试
. 时间序列中多断点的测试
. 多组广义 SEM
. 异方差的线性回归
. Heckman风格的样本选择Poisson模型
. 具有随机系数的面板数据非线性模型
. 贝叶斯面板数据模型
. 随机系数的面板数据区间回归
. SVG的导出
. 贝叶斯生存模型
. 零膨胀有序概率
. 添加您自己的电源和样本大小的方法
. 贝叶斯样本选择模型
. 支持瑞典语
. 对DO文件编辑器的改进
. 流随机数生成器
. 对于java插件的改进
. Stata / MP更多的并行化
科学软件网不定期举办各类公益培训和讲座,让您有更多机会免费学习和熟悉软件。
http://turntech8843.b2b168.com


























