使用期限租赁或*
许可形式单机和网络版
原产地美国
介质下载
适用平台window,mac,linux
科学软件网提供的软件覆盖各个学科,软件数量达1000余款,满足各高校和企事业单位的科研需求。此外,科学软件网还提供软件培训和研讨会服务,目前视频课程达68门,涵盖34款软件。
In Stata 16, we introduce a new, unified suite of commands for modeling choice data. We have added new commands for summarizing choice data. We renamed and improved existing commands for fitting choice models. We even added a new command for fitting mixed logit models for panel data. And we document them together in the new Choice Models Reference Manual.
And here’s the best part: margins now works after fitting choice models. This means you can now easily interpret the results of your choice models. While the coefficients estimated in choice models are often almost uninterpretable, margins allows you to ask and answer very specific questions based on your results. Say that you are modeling choice of transportation. You can answer questions such as
• What proportion of travelers are expected to choose air travel?
• How does the probability of traveling by car change for each additional $10,000 in income?
• If wait times at the airport increase by 30 minutes, how does this affect the choice of each mode of transportation?
What else is new? You now cmset your data before fitting a choice model. For instance,
. cmset personid transportmethod
Then, you use cmsummarize, cmchoiceset, cmtab, and cmsample to explore, summarize, and look for potential problems in your data.
And you use cm estimation commands to fit one of the following choice models:
• cmclogit conditional logit (McFadden’s choice) model
• cmmixlogit mixed logit model
• cmxtmixlogit panel-data mixed logit model
• cmmprobit multinomial probit model
• cmroprobit rank-ordered probit model
• cmrologit rank-ordered logit model
Unlike the others, cmxtmixlogit is not renamed and improved. It is completely new in Stata 16, and
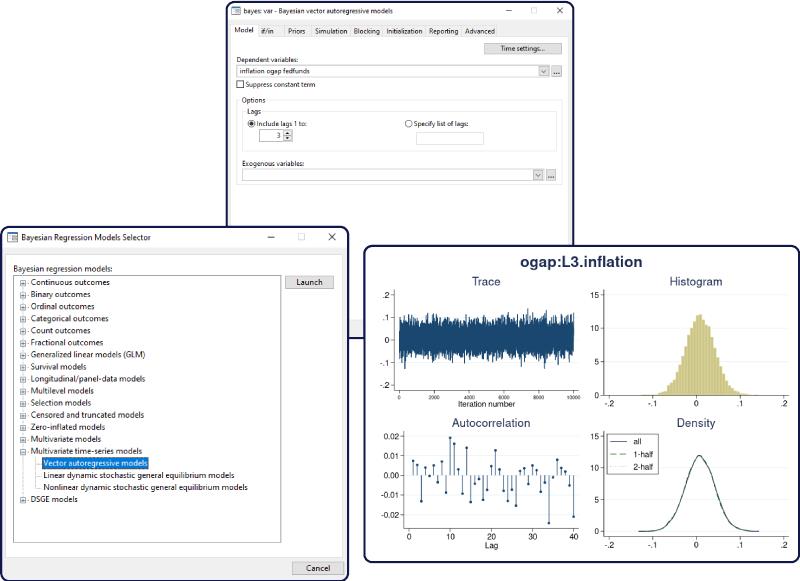
Bayesian and frequentist approaches have very different philosophies about what is considered fixed
and, therefore, have very different interpretations of the results. The Bayesian approach assumes that
the observed data sample is fixed and that model parameters are random. The posterior distribution
of parameters is estimated based on the observed data and the prior distribution of parameters and is
used for inference. The frequentist approach assumes that the observed data are a repeatable random
sample and that parameters are unknown but fixed and constant across the repeated samples. The
inference is based on the sampling distribution of the data or of the data characteristics (statistics). In
other words, Bayesian analysis answers questions based on the distribution of parameters conditional
on the observed sample, whereas frequentist analysis answers questions based on the distribution of
statistics obtained from repeated hypothetical samples, which would be generated by the same process
that produced the observed sample given that parameters are unknown but fixed. Frequentist analysis
consequently requires that the process that generated the observed data is repeatable. This assumption
may not always be feasible. For example, in meta-analysis, where the observed sample represents the
collected studies of interest, one may argue that the collection of studies is a one-time experiment.

In Bayesian analysis, we can use previous information, either belief or experimental evidence, in
a data model to acquire more balanced results for a particular problem. For example, incorporating
prior information can mitigate the effect of a small sample size. Importantly, the use of the prior
evidence is achieved in a theoretically sound and principled way.
By using the knowledge of the entire posterior distribution of model parameters, Bayesian inference
is far more comprehensive and flexible than the traditional inference.
Bayesian inference is exact, in the sense that estimation and prediction are based on the posterior
distribution. The latter is either known analytically or can be estimated numerically with an arbitrary
precision. In contrast, many frequentist estimation procedures such as maximum likelihood rely on
the assumption of asymptotic normality for inference.

Sample-size analysis for confidence intervals in Stata 16
The new ciwidth command performs Precision and Sample Size (PrSS) analysis, which is sample-size analysis for confidence intervals (CIs). This method is used when you are planning a study and you want to optimally allocate resources when CIs are to be used for inference. Said differently, you use this method when you want to estimate the sample size required to achieve the desired precision of a CI in a planned study.
ciwidth produces sample sizes, precision, and more that are required for the
• CI for one mean
• CI for one variance
• CI for two independent means
• CI for two paired means
The control panel interface lets you select the analysis type and input assumptions to obtain desired results.
ciwidth allows results to be displayed in customizable tables and graphs.
ciwidth also provides facilities for you to add your own methods.
19年来,公司始终秉承、专注、专心的发展理念,厚积薄发,积累了大量的人才、技术以及行业经验,在行业内得到了大量用户的认可和高度价。
http://turntech8843.b2b168.com


























